How LLMs Actually Work 
No math. No PhD. Just interactive demos that show you what's happening under the hood when you talk to AI.
1. What's a Token?
AI doesn't read words — it reads tokens. A token is usually a piece of a word, a whole word, or punctuation. Type anything below and watch it get split into tokens in real-time.
2. Context Window = Short-Term Memory
An LLM can only "remember" a fixed amount of text at once — its context window. Everything you send (your prompt, the conversation history, system instructions) has to fit inside it. When it fills up, older stuff gets forgotten.
Here's what that looks like in practice. When you use an AI coding tool like Claude Code, the context window isn't just holding your message — it's packed with system prompts, memory files, tool definitions, and the entire conversation history. Your actual working space is whatever's left over.
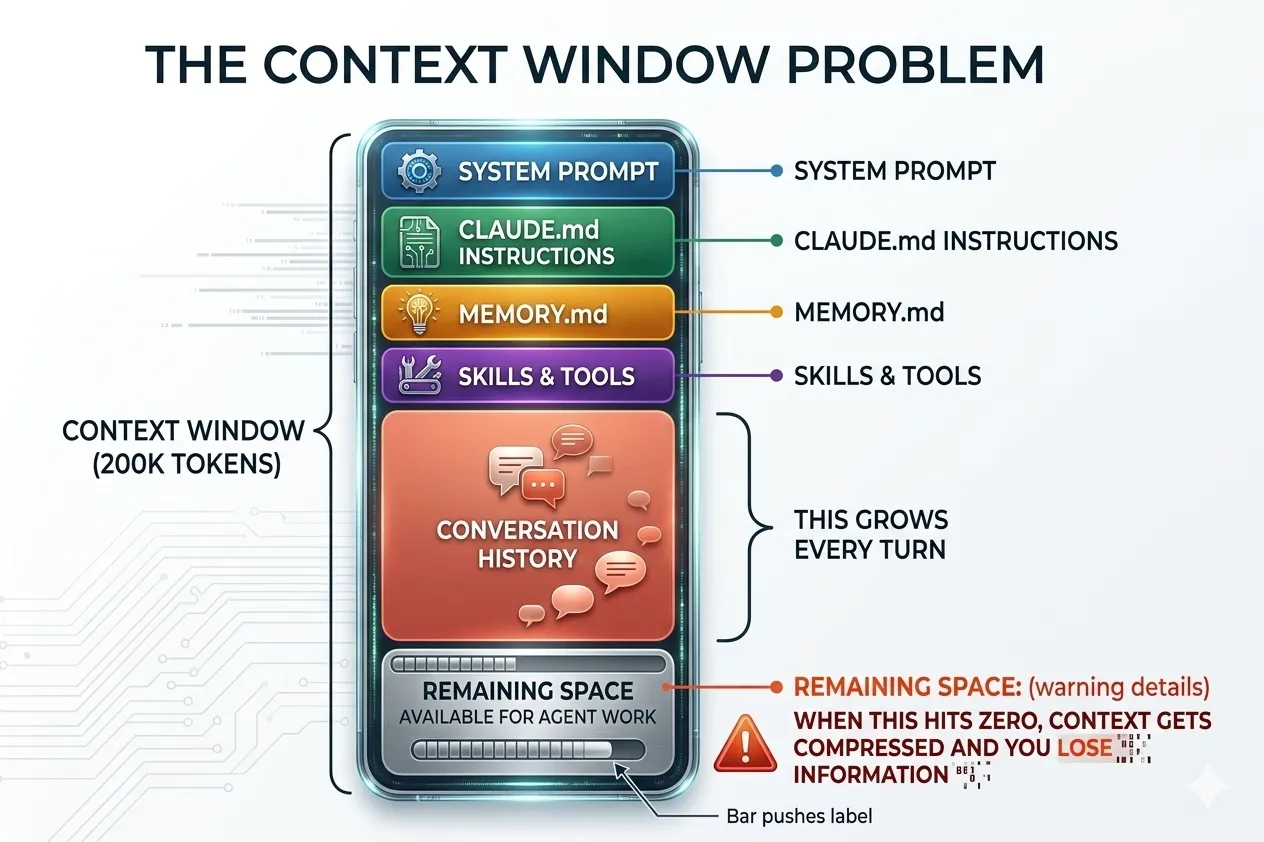
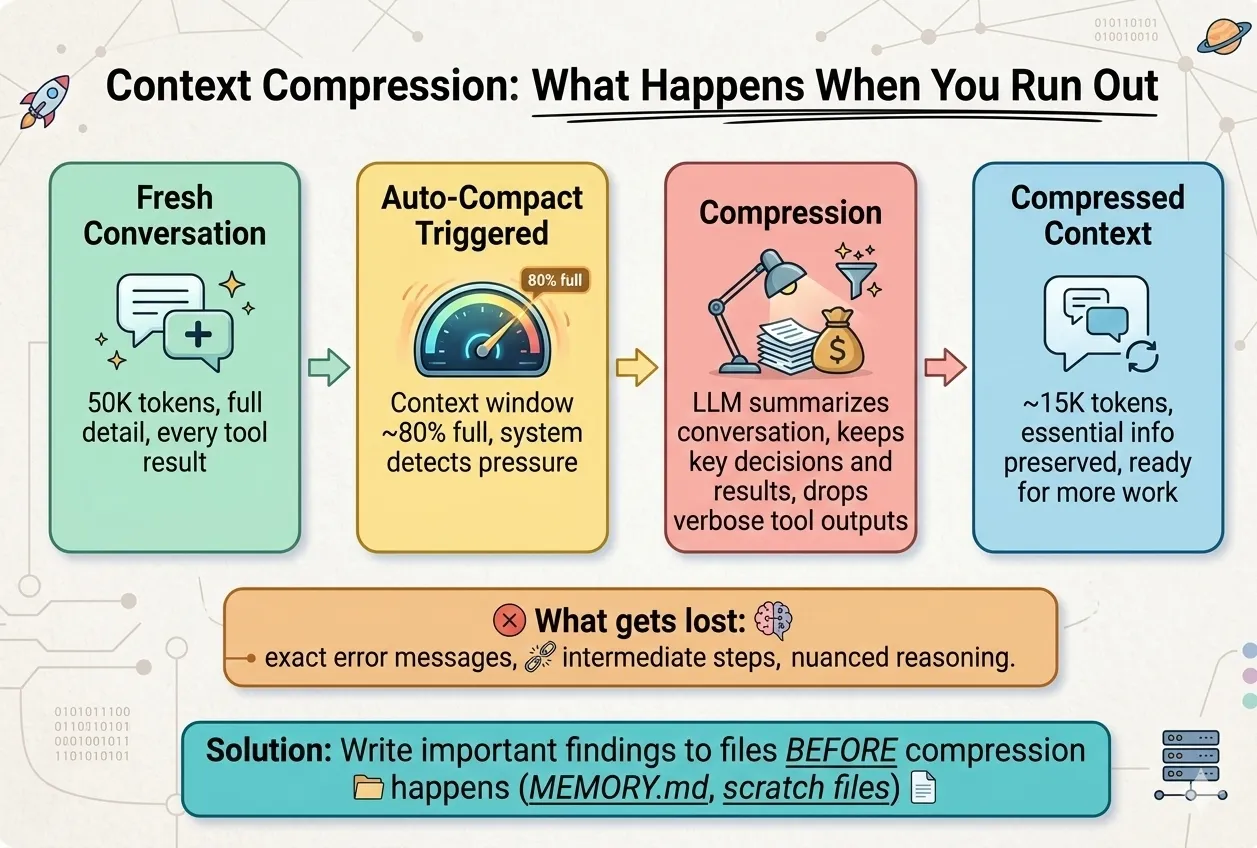
So what happens when you hit the limit? The AI doesn't just stop — it compresses. It summarizes the conversation to free up space, but that means details get lost: exact error messages, intermediate steps, nuanced reasoning. The bigger your context window, the longer you can go before this kicks in.
3. Attention: How AI Connects the Dots
When generating each word, the model doesn't treat all input equally. It pays attention to the most relevant parts. Click any word below to see what the model would focus on when generating from that position.
4. What Happens When You Hit Send
From the moment you press Enter to the moment you see a response — here's every step, in order.
5. Temperature = Creativity Dial
Every AI model has a temperature setting (0.0 to 1.0) that controls randomness. At low temperature, the model always picks the most likely next word — safe, consistent, boring. At high temperature, it takes bigger creative risks — sometimes brilliant, sometimes nonsense. Move the slider and watch the same prompt produce wildly different outputs.
"Write a one-sentence tagline for a new productivity app."
Key Takeaways
They predict the next token based on everything before it. That's the entire trick — it just works shockingly well at scale.
The model forgets everything between conversations. If you want it to "remember," you have to send the context every time (or use RAG — that's the next lesson).
The model physically "attends" to different parts of your input. Clear structure (headers, XML tags, examples) gives it better anchors to focus on.
The model always picks the most probable next token. It has no way to say "I don't know" — it will always generate something, even if it's wrong.